You can get an article like this one, maybe a little more background checked and neutral, just by asking ChatGPT. Or, better yet, you can ask ChatGPT to summarize this article.
So why read this? And if you don’t read this but use an LLM to summarize, then why should I write it nicely out in the first place. I could just put bullet points up here and it would be easier for both me and the LLM. That’s the shift that we are going through. And I’ve been writing about The Shift for a long time now, but alway only bits and pieces. In this writeup I’ll try to put those together to draw a bigger, personal picture of the future of the web in an LLM focussed world. This is not about zero touch computer interaction or the web for communication or the internet in general – I have my separate thoughts on those topics. This is about howwebsites as we know them might evolve.
Simple websites
People have started noticing a new years back that most sites don’t need fancy layouts and that unnecessary design is often decreasing conversion. I am going to cite a paragraph from an old article of mine –
[Simple sites] load faster. You find what you came for. You read. You click. You buy. You leave. That’s conversion.
As much as page builders try to sell you on unlimited design flexibility, having a more complex design just for the sake of it doesn’t solve anything.
A restaurant site with ten full-screen sliders, a cookie banner and giant popup doesn’t bring anything to the table if the user ends up searching the opening hours for 5 minutes. […]. Design should follow purpose.
That doesn’t mean that all websites should look plain or stripped down. The web thrives on personality. Color, playfulness, creativity – all good and needed. But when form hides function, people leave.
And this sentiment about simple sites is only carried on in an LLM-focussed world. When less people visit your site, it doesn’t matter if your site looks fancy or not, because a crawler sees the HTML output of a site. And those crawlers have an easier time analyzing your site if they don’t need to parse 10 nested divs to get the price of a sandwich. As a result, the AI preferably uses content of clean, simple sites preferably which results in more leads.
And more and more people are noticing. Dave Bloom and Kevin Geary just replaced their complex sites with a simple one. And while I don’t particularly like the new design (color, font choices), he is right about it not mattering too much. His personal site isn’t selling anything, there’s no need to impress.
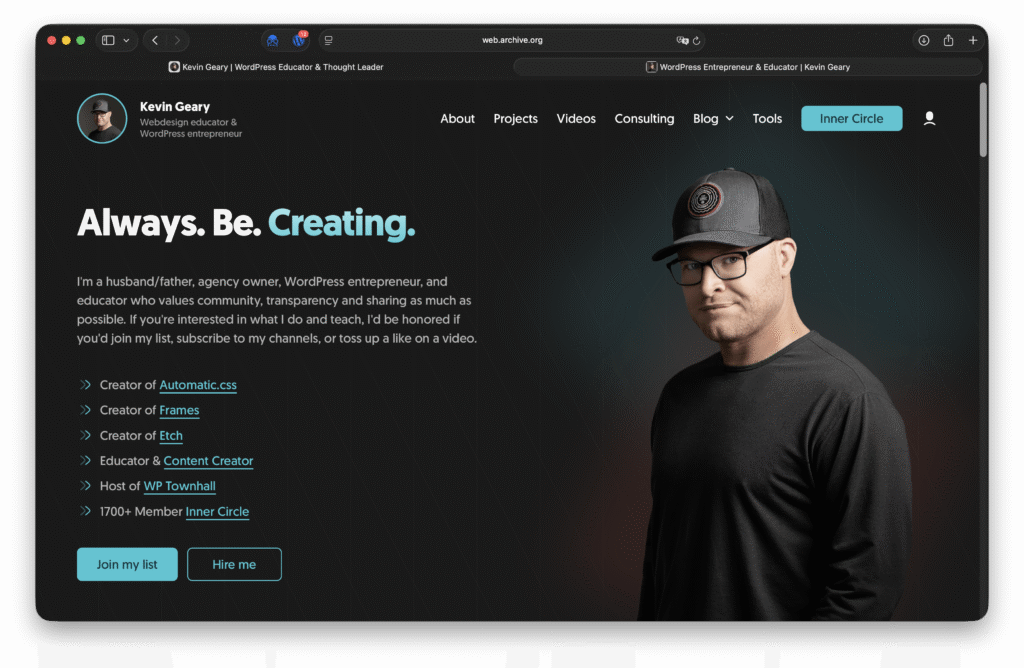
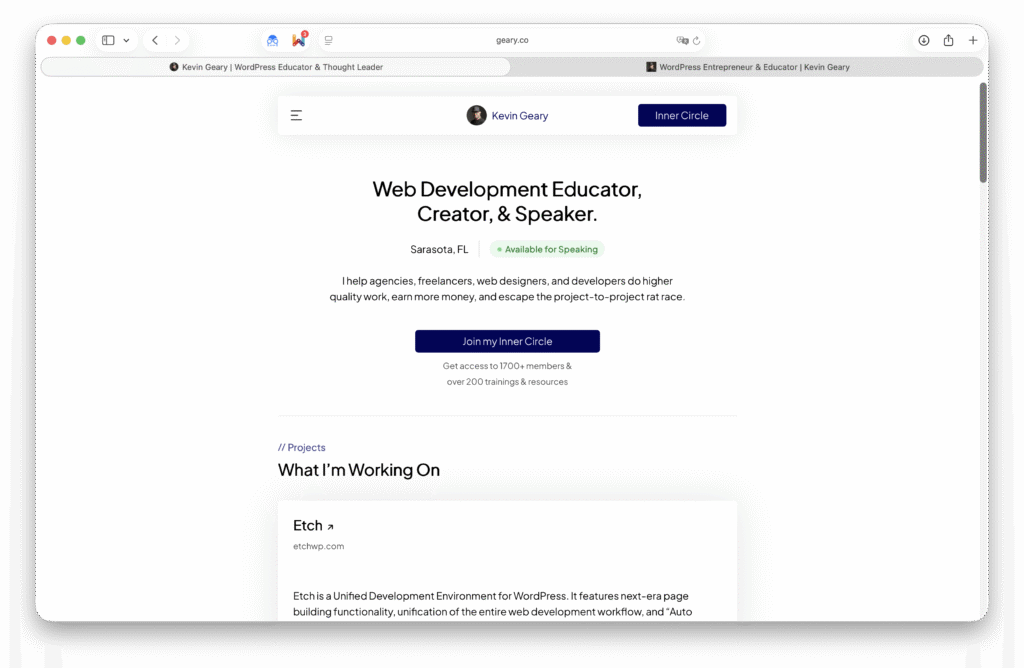
A current workaround/proposed solution for AI to “read” complex websites is to introduce /llms.txt files to all websites that explain the websites content for LLMs to understand. This is not only a bad solution because it separates content that AI sees from what we see, but also because it is a solution for a problem that shouldn’t exist in the first place.
The frontend-less web
If less and less people are accessing the websites themselves, eventually the frontend of websites might fade entirely. Why bother even building a simple frontend if people never visit your site? Why not just upload plain Markdown files directly?
That’s exactly where I see the future of web browsers headed. When a site is visited that doesn’t provide a frontend, it is the browsers responsibility to hold an on device AI to parse the provided contents and generate a frontend for the site. A simple one. Just something a person accessing a domain directly can read and see.
Single source of information?
I like the idea of everybody being able to set up their own web space. It provides freedom and means that nobody is in control. In an effort to find the most effective way of handling text and data in another writeup about the future or text in general, I wrote
We need a global knowledge cloud where the entirety of information is stored and where every LLM has access to. Think Wikipedia but bigger, and with private pages nobody can update. Nobody can own this knowledge cloud, just like nobody manages crypto. Updated in real time and all AI systems can access public entries – without needing to waste resources sifting through the entire web.
Nobody would own it, everyone’s in control, and yet it’s secure. But is all of that really necessary? Doesn’t Perplexity already search the web pretty well? Do we even want that giant brain? And could we even build this form of a knowledge cloud? Where is it stored? But then again, where is the BTC blockchain stored? I simply don’t know, but this is where we get into Web3 territory, a thing that went forgotten in the past years.
In the meantime, I like our domain based system.
PS: I recommend those write-ups as well
- Protecting Publishing in an LLM Era
- What comes after text – how can we store information more efficiently in the Al era?
Thank you for reading – feel free to share your thoughts down below!
Fabian